Challenge 16: CBC bitflipping attacks¶
Generate a random AES key.
Combine your padding code and CBC code to write two functions.
The first function should take an arbitrary input string, prepend the string:
"comment1=cooking%20MCs;userdata="
... and append the string:
";comment2=%20like%20a%20pound%20of%20bacon"
The function should quote out the ";" and "=" characters.
The function should then pad out the input to the 16-byte AES block length and encrypt it under the random AES key.
The second function should decrypt the string and look for the characters ";admin=true;" (or, equivalently, decrypt, split the string on ";", convert each resulting string into 2-tuples, and look for the "admin" tuple).
Return true or false based on whether the string exists.
If you've written the first function properly, it should not be possible to provide user input to it that will generate the string the second function is looking for. We'll have to break the crypto to do that.
Instead, modify the ciphertext (without knowledge of the AES key) to accomplish this.
You're relying on the fact that in CBC mode, a 1-bit error in a ciphertext block:
- Completely scrambles the block the error occurs in
- Produces the identical 1-bit error(/edit) in the next ciphertext block.
Stop and think for a second.
Before you implement this attack, answer this question: why does CBC mode have this property?
The diagram below illustrates how an error (or intentional edit!) in a ciphertext block affects the subsequent decrypted plaintext block in the corresponding position by simple XOR.
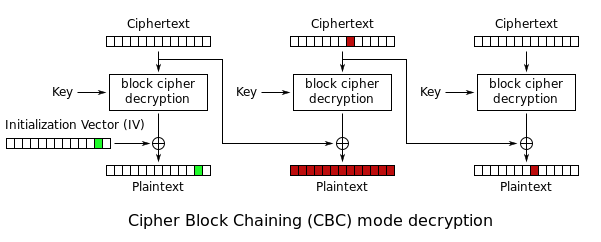
So the strategy is this. If we know that a particular string appears in the plaintext, and at what position, we can exploit this knowledge by XOR-ing the string with the desired replacement string (";admin=true;" in this case) to compute a kind of delta, and then XOR the delta with the corresponding ciphertext in the preceding block to effect that change.